FAQs
1
What is machine learning?
Machine learning is a branch of artificial intelligence that enables computer systems to identify patterns in data and refine performance over time without being explicitly reprogrammed.
At PersonaPanels, machine learning is used to build and maintain Synthetic Respondents that represent defined audience segments and evolve as they integrate new information.
2
What is a Synthetic Respondent?
A Synthetic Respondent is an AI-driven model representing a defined population segment. Built using validated human research data, Synthetic Respondents simulate how specific groups evaluate information and respond to new inputs.
They support both structured testing (KnowNow) and continuous market signal integration (Monitoring).
3
How are Synthetic Respondents Structured?
Synthetic Respondents are built around organized sets of interests and characteristics derived from research data. These interests are structured in a taxonomy that reflects how topics relate to one another within a defined segment.
The below is a simplifed visual represention of how interest areas are organized within a Synthetic Respondent. In practice, each model reflects a more detailed and research-informed structure.
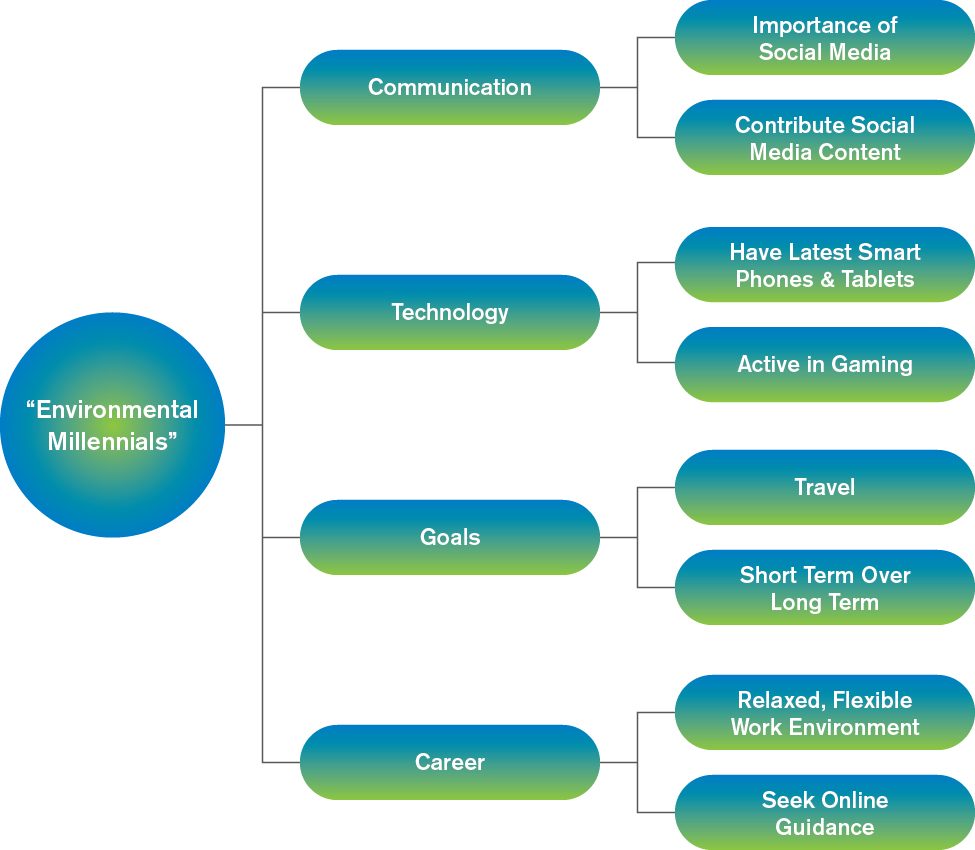
4
How do Synthetic Respondents stay current?
After creation, Synthetic Respondents integrate publicly available, text-based online content consistent with the interests of the segment they represent. Information that aligns with their defined characteristics may influence future responses.
This allows Synthetic Respondents to reflect evolving themes and narratives within their modeled population segments.
5
What is the difference between KnowNow and Monitoring?
KnowNow allows clients to test messaging, positioning, and strategic ideas against defined audience segments.
Monitoring continuously integrates relevant online content into a structured database. Clients can examine emerging themes and export data for analysis using their own tools and prompts.
KnowNow supports active testing. Monitoring supports ongoing market visibility.
6
How are message "interest scores" calculated?
When a client presents a message or concept to a Synthetic Respondent, the model evaluates alignment between the message content and the Synthetic Respondent’s defined and evolving characteristics.
The resulting score reflects the degree of alignment at that moment in time.
The illustration below demonstrates how a client message may overlap with a Synthetic Respondent’s structured interest areas. In practice, evaluation reflects both stable attributes and more recently integrated influences
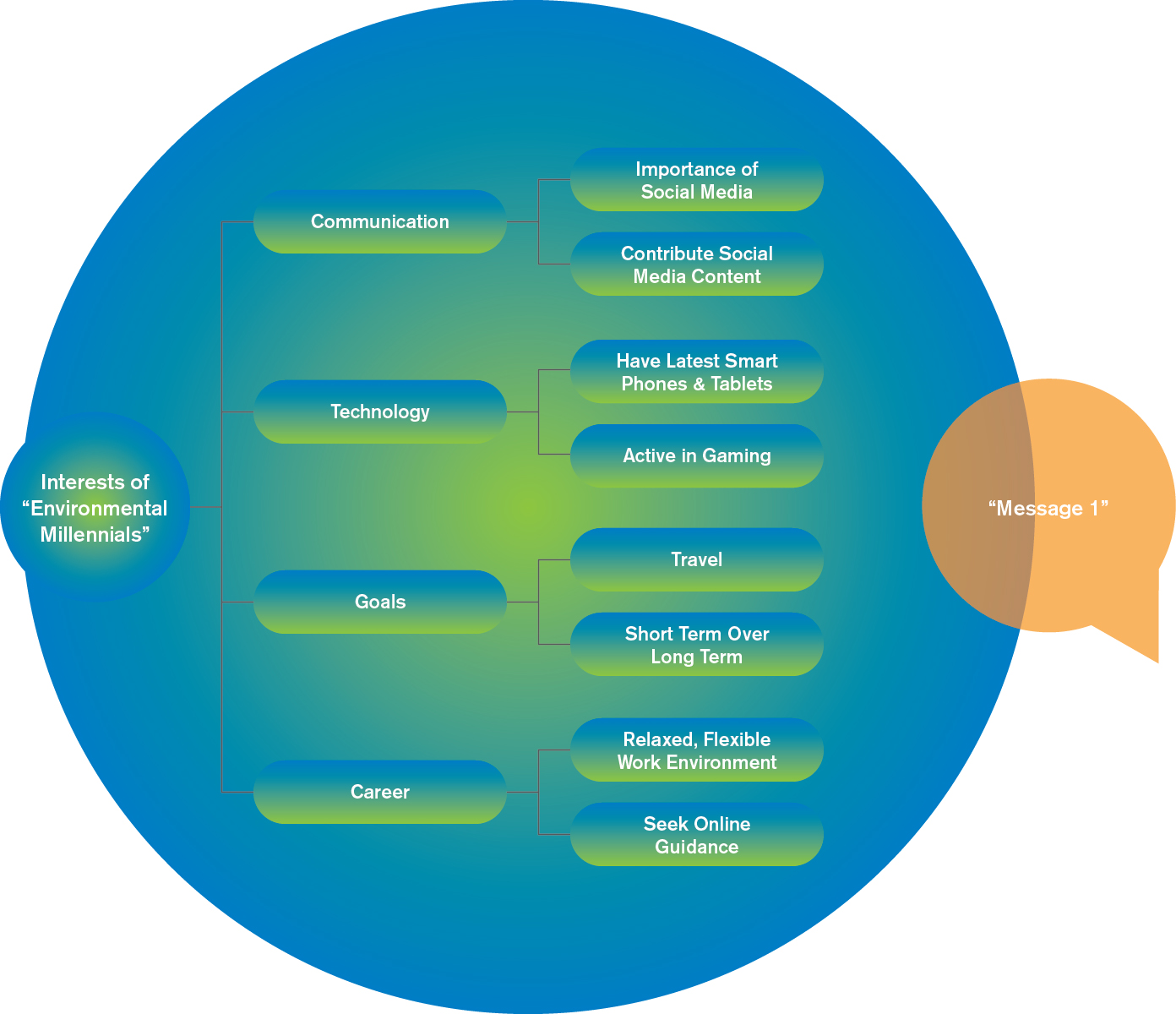
7
Are Synthetic Respondents real people?
No. Synthetic Respondents are AI-driven models built from aggregated research data. They represent defined population segments, not individuals.
8
Can we use our own research data?
Yes. Customized Synthetic Respondents may incorporate client-provided proprietary research data. Pre-constructed panels use a standardized methodology that can be modified with client data inputs if desired.
9
Do you provide prompts or LLM analysis tools?
No. PersonaPanels provides structured modeling and data outputs. Clients may export Monitoring data and analyze it using their own preferred tools, including external language models, using prompts they define themselves.
10
How quickly can we begin?
Pre-constructed panels are available immediately.
Customized Synthetic Respondents require a development phase. Newly created models are typically allowed to integrate online content for a short period before testing begins.
11
Do Synthetic Respondents access social media platforms?
No. Synthetic Respondents do not access large social media platforms (such as Facebook) or closed networks requiring login access.
Synthetic Respondents integrate publicly available, text-based online content. They do not evaluate video-only posts unless a text transcription is available.
Standalone blogs and publicly accessible websites can be integrated. However, content embedded within larger domains (for example, a blog hosted as a subpage of a major media site) may not be accessed directly.
This approach maintains consistency, transparency, and compliance with platform access restrictions.
12
Can Synthetic Respondents process images or audio?
Currently, Synthetic Respondents operate on text-based content. If visual or audio material is transcribed into text, it can be evaluated.
13
Can results be compared to human research?
Like traditional research, Synthetic Respondent testing is most useful directionally.
PersonaPanels validation work indicates that when Synthetic Respondents and human respondents represent the same population segment during the same time period, results tend to be directionally similar.
14
Do Synthetic Respondents replace traditional research?
No. Synthetic Respondents are designed to complement traditional research methods, not replace them.
Organizations often use Synthetic Respondents to narrow product or messaging options before conducting human fieldwork, refine ideas between research waves, explore strategic scenarios directionally, or maintain ongoing insight in a cost-efficient way.
Traditional research remains valuable for final validation and direct human feedback. Synthetic Respondents help teams make more informed decisions before committing time and budget to those efforts.
15
What types of research are most appropriate?
Synthetic Respondents are particularly well suited for:
- Concept testing
- Messaging evaluation
- Strategic scenario exploration
- Monitoring evolving themes within defined segments
They are not appropriate for research requiring recall of personal experiences (for example, post-sales representative interactions).
16
Are Synthetic Respondents confidential?
Yes. All modeling and data integration occur within a controlled environment. Client-provided data is handled confidentially.
17
What are the advantaged compared to traditional research?
Synthetic Respondents offer:
- Rapid iteration
- No respondent fatigue
- Continuous availability
- Ongoing integration of evolving themes
- Confidential evaluation of sensitive mateiral
- Predictable subscription-based access
They are designed to strengthen research workflows, not replace them.
18
What company developed the underlying technology?
PersonaPanels works with UltiSim .com to support the machine learning infrastructure underlying the platform.
19
Has PersonaPanels established partnerships?
Yes. PersonaPanels collaborates with select partners to support data sourcing and platform infrastructure.
These partnerships include organizations that supply human panel data, behavioral data, and machine learning infrastructure used int he development and operation of Synthetic Respondents.
See the Our Partners page for additional details.
If you have a specific question not covered by this FAQ, please use this contact form. Someone from our team will reply with your answer.